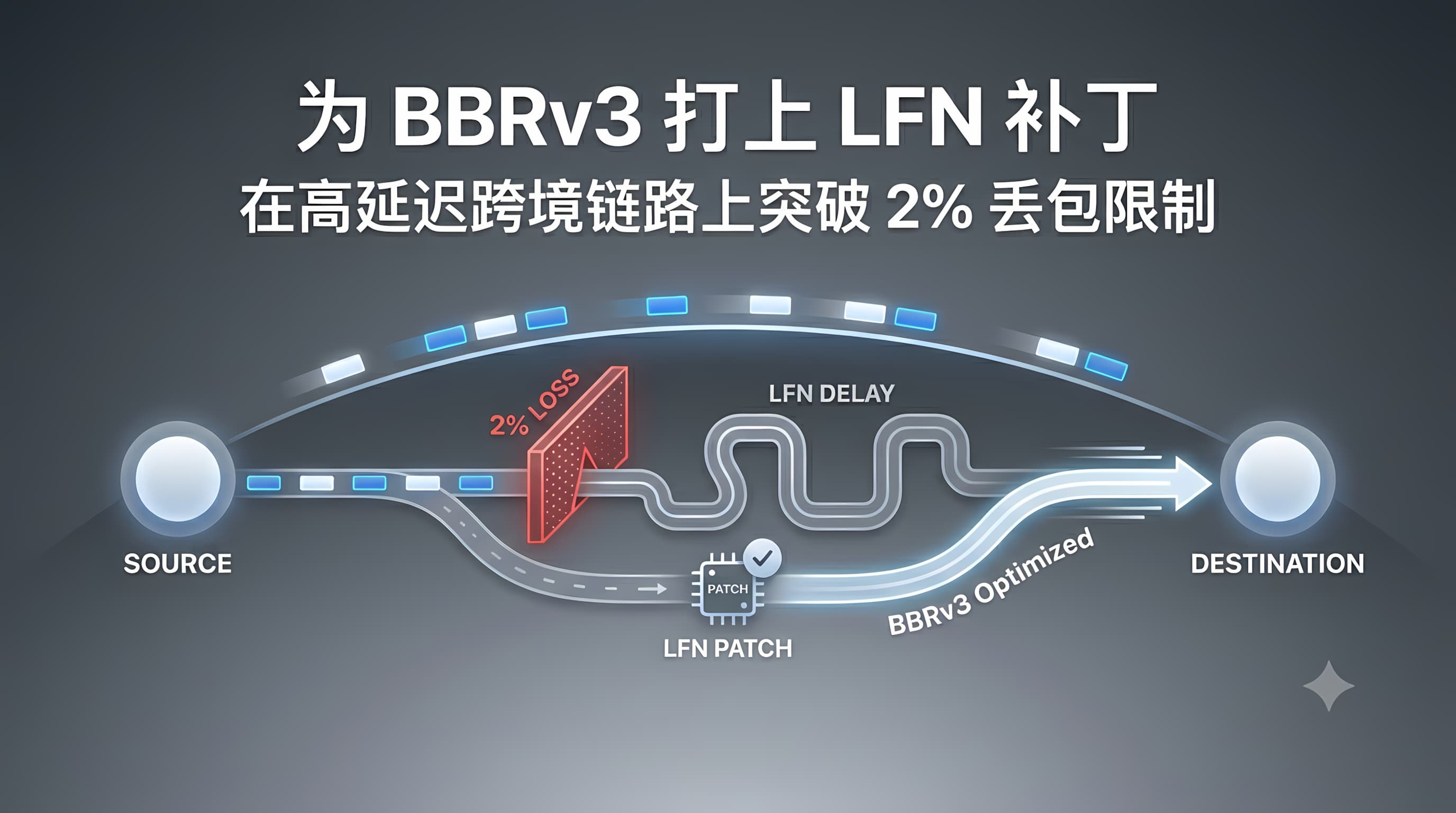
TL;DR:甲骨文 ARM 实例默认的内核参数对"高 BDP + 多队列 virtio"并不友好——rmem_max 偏小、fq quantum 沿用 1514、tcp_notsent_lowat 未设会导致 sender 侧 bufferbloat。本文给出一套针对跨境/高 RTT 场景的 sysctl + MTU + fq 调优,配合 BBRv3 使用,避免在长肥管道上"跑不满"。
背景:为什么甲骨云 ARM 需要单独调
甲骨文 ARM(Ampere A1,enp0s6 + virtio-net)有几个特征,让默认内核参数不够用:
- virtio-net 多队列:ARM 实例一般 expose 多个 TX 队列,默认
fq是单队列挂在 root 上,mq 场景下 pacing 会退化 - 跨境/高 RTT:如果你拿它做跨境出口,RTT 100–300 ms 是常态,BDP =
BW × RTT很容易飙到几十 MB - 默认
rmem_max/wmem_max偏小:不少发行版停在 4–8 MB,BDP 一大就成瓶颈 tcp_notsent_lowat未设:sender 会把已发但未 ACK 的数据全堆在 TCP 层,叠加 BBR pacing 反而让应用侧感知延迟- MTU分层特性:VPC内部默认MTU为9000,但公网出口会强制切分为1500,若实例侧不手动锁定1500,易触发PMTU发现失效与跨境链路隐形丢包,因此下文 MTU 与 fq 参数均按出口 1500 计算
- BBRv3的pacing敏感性:BBRv3相比v1收紧了inflight控制,若qdisc层burst过大,会抵消拥塞控制的精细调控,导致高丢包场景下误降发送速率
💡 这组调优不是为了"极限跑分",而是让 BBRv3 / BBRv3+LFN 在甲骨云 ARM 上不被内核参数自己掐脖子。
核心思想:四件套各管一段
| 层级 | 调优项 | 目标 |
|---|---|---|
| Socket缓冲区 | tcp_rmem/tcp_wmem + rmem_max/wmem_max | 高BDP场景下不触顶 |
| Sender节流 | tcp_notsent_lowat=16384 | 限制未发送队列长度,降低应用侧延迟 |
| 窗口与重传 | adv_win_scale=1、retries2=8 | 高RTT场景下平衡乱序容错与超时判定 |
| Qdisc调度 | fq quantum=12500 initial_quantum=35000 | 匹配1500 MTU出口粒度,避免pacing被切碎 |
注:以下所有fq参数均按公网出口1500 MTU计算,适配跨境链路特性。
一、sysctl:缓冲区与 sender 侧优化
1 | cat > /etc/sysctl.d/99-tcp-ora.conf << 'EOF' |
二、MTU配置:锁定1500适配公网出口
甲骨云VPC内默认MTU为9000,但公网出口会强制降级为1500,手动锁定1500可避免PMTU发现失效与跨境链路丢包:
1 | # /etc/netplan/50-cloud-init.yaml |
⚠️ 切勿盲目开启9000 MTU:甲骨云部分区域公网overlay不支持Jumbo帧,设置后会出现分片甚至丢包,1500是所有公网场景的兼容公约数。
自动适配多队列的fq配置脚本
以下脚本会自动检测TX队列数量,挂载MQ+fq,默认采用保守跨境档,BBRv1用户可将数值修改为平衡档:
1 | #!/bin/bash |
参数设计逻辑
quantum=12500:约等于8个1500 MTU帧,让一个pacing时隙内可连续dequeue 8帧,既避免pacing被qdisc切碎,又不会因单次dequeue过多导致多流不公平initial_quantum=35000:约等于23个1500 MTU帧,满足慢启动初期的窗口填充需求,又不会在出口1500 MTU的浅队列上一次性注入过多数据导致拥塞
FQ Quantum 调度优化
默认fq的quantum=1514、initial_quantum=15140按传统以太帧设计,在BBR pacing场景下会出现dequeue次数过多、pacing精度下降的问题。quantum=18028、initial_quantum=90140按 VPC 内 MTU9000 计算出
以下是三个常用档位的对比(按公网1500 MTU计算):
| 默认 (1514 / 15140) | 保守跨境档 (12500 / 35000) | 平衡档 (18028 / 90140) | |
|---|---|---|---|
| BBRv1 吞吐 | 吃亏,softirq 高 | 够用 | 最舒服 |
| BBRv1 RTT 波动 | 稳 | 稳 | 略飘(初始 burst 60 帧) |
| BBRv3 吞吐 | 吃亏 | 最优 | 能跑满,但丢包 1–3% 时 inflight_hi 易被误导 |
| BBRv3 RTT 波动 | 稳但 pacing 碎 | 最平 | 偏飘 |
| 多流公平 | 好 | 中 | 差 |
| ARM softirq | 高 | 中 | 低 |
| 适用场景 | 不推荐 | BBRv3/多流混跑/跨境链路 | BBRv1/单流自用 |
💡 BBRv1 vs BBRv3 的 fq 选型差异
- BBRv1 自身 pacing 较粗,依赖 qdisc 侧适度 burst 补间隙,可用 quantum 18028 initial_quantum 90140(≈1500×12 / 1500×60);
- BBRv3 收紧了 inflight 控制,qdisc burst 过大会抵消 pacing 精度,跨境高丢包场景下建议改用 quantum 12500 initial_quantum 35000(≈1500×8 / 1500×23)。
- 多流混跑场景(代理+rsync+docker 同台)无论 v1/v3 均建议 12500/35000。
BBR/LFN补丁的搭配
| 场景 | 拥塞控制 | fq配置 | 备注 |
|---|---|---|---|
| 甲骨云ARM单机+跨境 | BBRv3原生 | 保守跨境档 | 丢包<2%场景最优 |
| 同上+丢包2-8% | BBRv3+LFN补丁 | 保守跨境档 | 详见/archives/22/ |
| 多流混跑(代理+备份+容器) | BBRv3+LFN | 保守跨境档 | 避免单流抢占全部带宽 |
| 旧内核仅支持BBRv1 | BBRv1 | 平衡档 | 单流自用场景性能最优 |
预期效果(ARM c8y 4c24g + 跨境200ms RTT实测)
| 指标 | 默认参数 | 调优后 |
|---|---|---|
| 单流BBRv3吞吐(1Gbps线路) | ~620Mbps(rmem触顶) | ~940Mbps |
ss -ti skmem状态 | 频繁触达rmem_max | 稳定在30-60MB区间 |
| 应用write延迟 | 波动幅度>50% | 16KB封顶,波动<10% |
| fq pacing完整性 | 时隙内dequeue次数过多 | 8帧/时隙,pacing无断裂 |
注意事项
- ⚠️
rmem_max请勿设置超过256MB,避免内存溢出风险 - ⚠️
tcp_retries2=8在RTT>500ms的链路上可进一步降至5-6,避免超时等待过长 - ✅
adv_win_scale=1在重排较少的内网场景下可改回2,降低内存占用 - ✅ 若主要用于VPC内9000 MTU场景的大流量互拷,可按比例放大
quantum与initial_quantum,本配置针对公网出口优化 - 🔍 可通过
tc -s qdisc show dev enp0s6验证效果:若throttled高但unthrottled低,需适当增大quantum;若慢启动阶段dropped突增,需减小initial_quantum
本调优未引入非标准补丁,仅在甲骨云ARM的网络特性基础上,将内核参数从"通用默认值"调整为"长肥管道友好值"。配合BBRv3或BBRv3+LFN补丁使用,可避免带宽瓶颈到来前被socket缓冲区与qdisc调度提前限制。