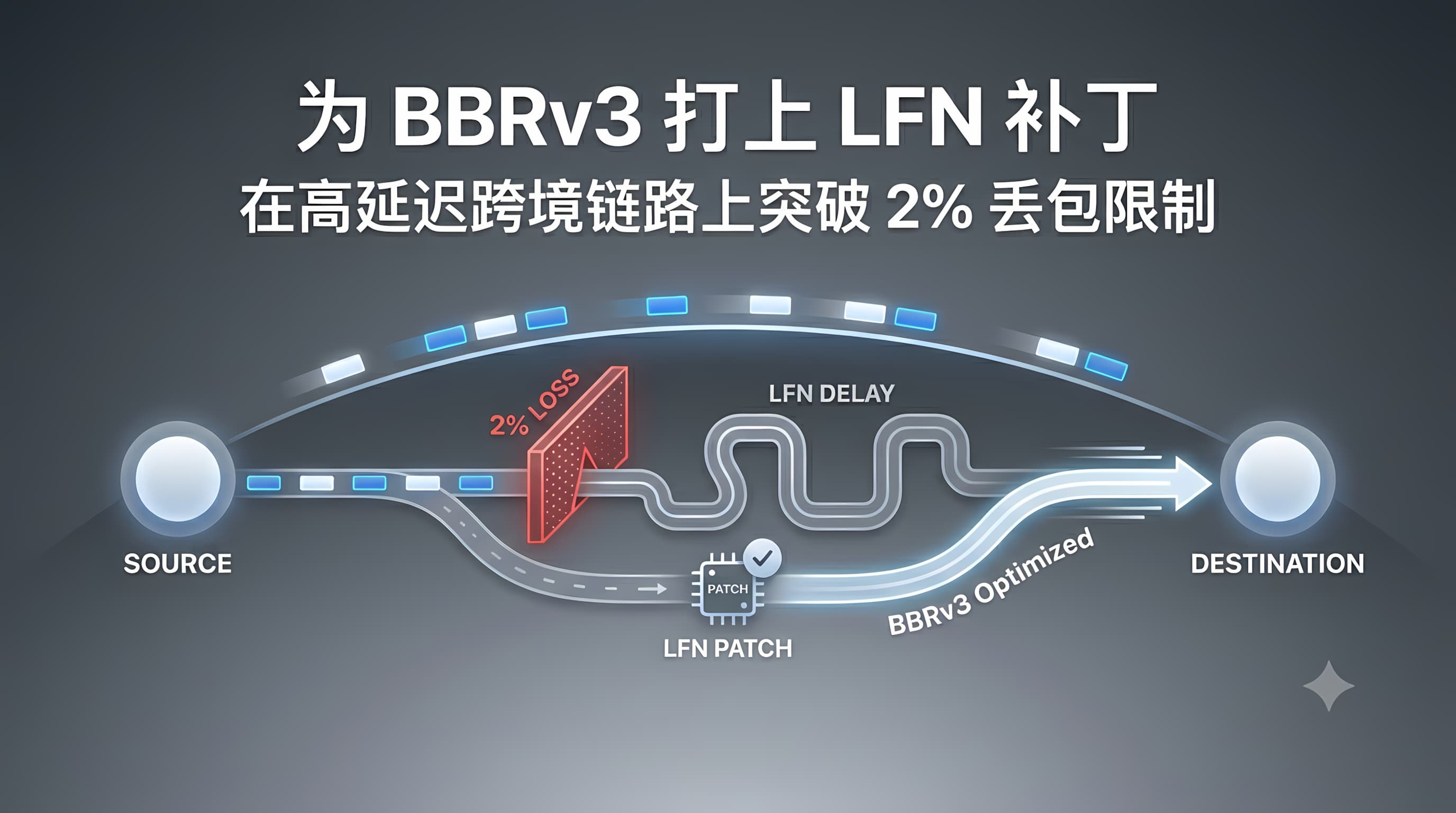
TL;DR:BBRv3 默认将丢包率上限锁死在 2%,这在跨境、卫星等长肥管道(LFN)上会严重限制吞吐量。本文介绍一个安全的可调参数补丁,允许在特定条件下放宽该限制,同时保持 AQM 友好性。
背景:BBRv3 的 2% 天花板
BBRv3 通过测量带宽和 RTT 来估计瓶颈容量,并在探测带宽时设置了一个硬性丢包上限:
static const u32 bbr_loss_thresh = BBR_UNIT * 2 / 100; /* 2% loss */
一旦丢包率超过 2%,BBR 会认为发生了拥塞,冻结 inflight_hi ,停止探测更高带宽。
这在数据中心和低延迟网络中非常合理,但在以下场景中却成了瓶颈:
- 跨境链路(中美/中欧):存在 2–5% 的稳定物理丢包
- 卫星链路:高 RTT + 随机丢包
- 高 BDP 链路:缓冲区深,但丢包并非总是拥塞
结果是:BBR 永远无法达到真实瓶颈带宽。
BBRv3 源码中 bbr_loss_thresh 定义见 google/bbr@90210de4为什么不切回 BBRv1?
虽然 BBRv1 没有 2% 的硬性丢包限制,但它存在两个致命缺陷:
- AQM 不友好:在 fq_codel / CAKE 等主动队列管理环境下,V1 容易填满缓冲,导致延迟飙升(Bufferbloat)。
- 公平性较差:V1 的 Probe Up 阶段过于激进,在高并发场景下会挤压 Reno/Cubic 及其他 BBR 流的生存空间。
因此,我们需要的是一个保留 BBRv3 的 AQM 友好性和公平性,同时修补其 LFN 缺陷的方案,而非简单地倒退版本。
核心思想:条件放宽,而非无脑放开
我们的补丁引入两个 sysctl参数:
1 | net.ipv4.tcp_bbr_lfn_loss_thresh_pct = 0 |
仅在满足以下 4 个条件时,才允许将 2% 放宽到 pct% :
| 条件 | 目的 |
|---|---|
mode == PROBE_BW && cycle_idx != PROBE_UP | 避开 RTT 滞后的探测上升期 |
rtt_us < 1.2 × min_rtt_us | 确认没有队列堆积 |
min_rtt_stamp新鲜(≤ 5s) | 防止使用陈旧的 RTT 基准 |
tx_in_flight ≤ 1.15 × BDP | 防止 AQM 丢包被误判为物理丢包 |
这四个条件构成了一个安全沙箱,确保只有在“看起来真的只是背景噪音丢包”时才放宽限制。
内核核心变更 / 实现细节
1. Sysctl 模块变更(net/ipv4/sysctl_net_ipv4.c)
新增两个全局 sysctl 变量,供 BBR 模块读取:
1 | int sysctl_tcp_bbr_lfn_loss_thresh_pct __read_mostly = 0; |
2. BBR 模块变更(net/ipv4/tcp_bbr.c)
在 bbr_is_inflight_too_high() 中加入动态阈值逻辑:
1 | pct = READ_ONCE(sysctl_tcp_bbr_lfn_loss_thresh_pct); |
3. 工程健壮性
- ✅ GCC/Clang 双兼容:采用内核标准
u32jiffies 减法,jiffies_to_msecs()自动扩展,无编译器特有语法 - ✅ jiffies 回绕安全:
u32减法天然处理回绕,符合内核惯用法 - ✅ 零开销:仅在发生丢包时读取 sysctl
- ✅ 无残留风险:sysctl 注册在内核核心,非模块私有
AQM 兼容性
很多读者会担心:“放宽丢包阈值会不会把队列撑爆?”
答案是:不会,因为补丁内置了三层 AQM 防护机制。
与 fq 的配合
- pacing
fq 提供硬件级 pacing,BBR 的 probe 节奏不受影响 - 隔离
每流独立队列,单流激进不会导致全局拥塞 - 建议值:
pct=5-7
与 fq_codel 的配合(最关键)
这是最容易出问题的组合,但补丁已针对性处理:
- CoDel 丢包 ≠ 物理丢包
fq_codel 在缓冲区满时会主动丢包,这会被 BBR 误判为拥塞。 - Inflight Roof(1.15×BDP)
补丁强制:只有当 tx_in_flight ≤ 1.15 × BDP时才放宽阈值。
如果已经在 1.15×BDP 以上还丢包,直接拒绝放宽,让 fq_codel 接管。 - 建议值:
pct = 5-7lfn_min_rtt_fresh_ms = 3000
与 CAKE 的配合
CAKE 是智能 AQM,会主动管理延迟和带宽:
- 延迟目标优先
CAKE 看到 inflight 过高会自动丢包,补丁的 roof 机制同样生效。 - 带宽感知
在diffserv4模式下,BBR 的 LFN 优化不会影响其他流。 - 建议值:
pct = 4-6lfn_min_rtt_fresh_ms = 5000
一句话总结
补丁从不对抗 AQM,它只是在 AQM 允许的“安全区”内,允许 BBR 忽略背景物理噪声。
AQM 搭配建议
BBRv3 本身已经自带 pacing,理论上只需要一个简单 FIFO + fq 就够了。但在跨境、高 RTT、随机丢包场景下,队列规则的选择会直接影响「吞吐稳定性」和「延迟抖动」。
| 队列规则 | 原生 BBRv3 | BBRv3 + LFN 补丁 | 适用场景 & 备注 |
|---|---|---|---|
| fq | ✅ 首选 pacing 原生匹配,CPU 占用最低 | ✅ 首选 LFN 在高丢包下仍保持 pacing 精度 | 甲骨文 ARM / 单机出口 / 带宽稳定环境 |
| fq_codel | ⚠️ 可用 丢包 >2% 时 BBRv3 会主动退让,CoDel 效果有限 | ✅ 推荐 LFN 放宽丢包阈值,CoDel 能真正压制 bufferbloat | 多流混跑 / 有突发流量的 VPS |
| cake | ❌ 不推荐 BBRv3 与 cake 的 pacing 叠加,容易造成“双限速”,吞吐下降 10–20% | ✅ 延迟优先 LFN 的 aggressiveness 可抵消 cake 的保守调度 | 卫星链路 / 弱网 / RTT > 150 ms |
| pfifo_fast | ❌ 不推荐 无 pacing,BBRv3 吞吐优势无法发挥 | ❌ 不推荐 即使 LFN 放宽丢包容忍,仍受限于无 pacing | 仅用于临时排查问题 |
一个关键认知差异(很多人会踩)
原生 BBRv3 在丢包 > 2% 时会明显收缩 inflight,此时无论你怎么调 AQM,吞吐都不会好看。
这也是为什么很多“跨境机器上了 BBRv3 却感觉没区别”的根本原因。
而 LFN 补丁的核心改动之一,就是把 BBRv3 的丢包容忍阈值从 ~2% 推到 5–10% 区间,并弱化 loss-based exit 逻辑。
在这种前提下:
cake不再“拖后腿”,反而能帮你压住跨国链路的 bufferbloatfq_codel在中等丢包下表现更稳定fq依旧是最稳妥的默认选择
💡 经验结论:
- 链路干净(丢包 < 1%、RTT < 80 ms)→ 原生 BBRv3 + fq,不用折腾 LFN
- 链路脏(丢包 2–8%、RTT 100–300 ms)→ BBRv3 + LFN + fq / cake
- 极端弱网(卫星 / 4G 转公网 / 丢包 > 10%)→ LFN + cake,放弃 fq
如果你正好落在第二、第三种情况,LFN 补丁会帮你走完“高丢包友好”的最后一步。
如何使用
1. 编译内核
2. 配置参数
写入 /etc/sysctl.d/99-bbr-lfn.conf :
1 | # BBR LFN: allow up to 10% loss in PROBE_BW if RTT<1.2x min_rtt & inflight<=1.15xBDP |
应用: sysctl --system
3. 推荐值速查
| 场景 | 推荐值 |
|---|---|
| 默认 / 数据中心 | 0(关闭) |
| 跨境 / 高 RTT | 5–7 |
| 卫星 / 极端 LFN | 10 |
| 实验环境 | 2–20 |
预期效果
| 指标 | 原版 BBRv3 | 补丁后 |
|---|---|---|
| 跨境 3-5% 丢包吞吐 | ❌ 受限 | ✅ 满速 |
| 队列敏感性 | ✅ 高 | ✅ 不变 |
| AQM(CAKE/fq_codel) | ✅ 友好 | ✅ 友好 |
| 突发拥塞反应 | ✅ 快 | ⚠️ 略慢 |
注:突发拥塞下"略慢"指 pct>0 时放宽阈值会让 BBR 多扛一小段丢包再降速,代价是瞬时 inflight 可能略超原版;在物理丢包为主的 LFN 链路上收益远大于此代价。
注意事项
- ⚠️ 不要在数据中心或低 RTT 链路上开启
- ⚠️ 不要设置
pct > 20 - ✅ 始终配合
inflight roof使用(补丁已内置) - ✅ 建议先在边缘节点进行灰度测试
总结
这个补丁并没有推翻 BBR 的设计哲学,而是在长肥管道的灰色地带里,给它一把更聪明的尺子。
默认关闭,按需开启;条件苛刻,绝不滥用。
如果你也在跨境或卫星链路上被 BBR 的 2% 天花板困扰,不妨试试这个补丁。
补丁地址:Linux-BBRv3-LFN-Patch
适用内核:Linux 6.13+(BBRv3 主线)
许可证:GPLv2(与 Linux 内核一致)
Happy hacking 🚀